DLSS4加持,经典再进化:iGame RTX 5080 AD OC评测

随着RTX 50系Blackwell GPU的正式发布,时隔两年之久的GPU大战再次打响,包括iGame在内的一众AIC厂商也带来了全套的新解决方案共襄盛举。这次我们游侠硬件组拿到了一张来自七彩虹的iGame GeForce RTX 5080 Advanced OC 16GB 16GB显卡,看看七彩虹这张高端经典的iGame显卡在Blackwell的加持下能够带来怎样的火花吧。
在介绍具体显卡之前,我们还是需要再简单过一下RTX 50系游戏GPU在架构层面的改进。本次RTX 50系游戏GPU搭载了NVIDIA最新的Blackwell架构,而基于NVIDIA以历史上有名的各位大神为GPU微架构起名的传统,本次Blackwell也是向著名数学家、统计学家,拉奥-布莱克韦尔定理的提出人戴维·哈罗德·布莱克韦尔的致敬。

由于半导体制造工艺以及商业可行的芯片尺寸逐渐逼近物理学极限,摩尔定律的终结已然是摆在台面上的不可忽视的问题。在RTX 50系Blackwell GPU上,NVIDIA引入了一个全新的概念-Neural Shaders神经网络着色器。
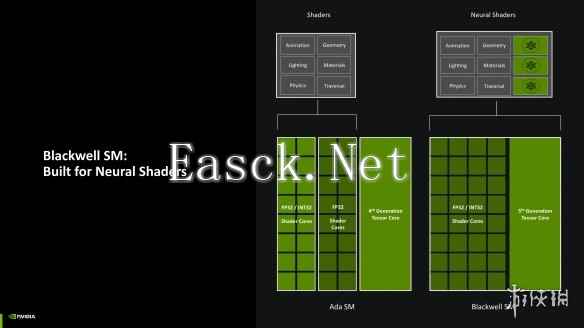
从名字上也可以看出来,本次Blackwell GPU的着色单元高度依赖AI算力,每一组Blackwell SM单元均是针对神经网络着色器架构进行特化的产物,与上一代Ada GPU SM单元仅有一半核心拥有INT32能力不同,在Blackwell上,每一组SM单元的着色器核心都能够执行FP32/INT32指令,搭配第五代Tensor Core与改进的着色器执行重排序(SER),能够显著提升显卡在运行包括DLSS在内的各种图形/AI负载时的效率。

在实际应用中,基于Blackwell GPU的Neural Shaders,开发者可以在游戏中部署基于神经网络的模型、贴图、材质与体积云等效果。开发者可以通过训练一个基础模型,在用户端进行实时推理的方式实现高质量、高效率且小体积的画面效果。与在本地完整烘焙光照、打包分发相比,采用基于Neural Shaders实现的AI着色同样也能显著提升游戏开发者的效率,可以说是让所有人都幸福的解决方案了。
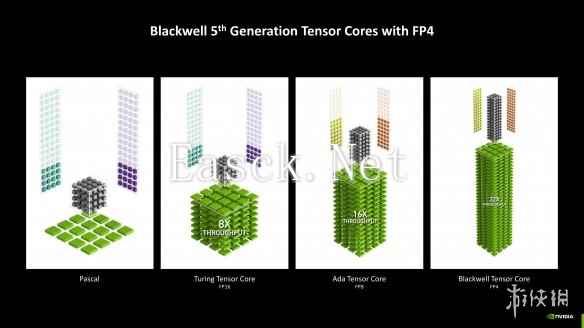
在面向包括DLSS在内的各路AI应用的Tensor Core上,本次Blackwell引入的第五代Tensor Core支持了更低精度的FP4规格数据,这能够进一步压缩负载时的显存压力,在显存池受限的消费级游戏GPU上更是能显著提升如DLSS等技术的效果表现。同时,对于近年来逐渐成为业界焦点的Transformer模型而言,第五代Tensor Core的效果也是相当出彩,这一点在后面讲DLSS 4的时候也会提及。
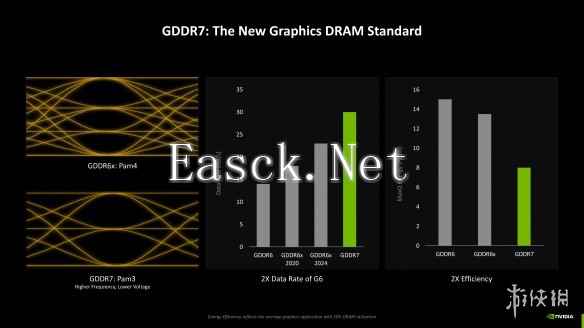
说到显存,本次RTX 50系GPU全系引入革命性的GDDR7显存。由于采用了PAM-3信号调制技术,GDDR7显存能够在实现更高频率的同时显著降低功耗,且提升幅度十分可观:根据NVIDIA的说法,RTX 50系首发搭载的GDDR7颗粒能够在带来两倍于GDDR6显存的性能同时仅消耗一半的能量,提升幅度相当显著。

大规模GPU的能耗问题在如今愈发显著,而Blackwell架构通过更精细的电压控制与频率切换可以说是大幅优化了这一点。

对于消费级GPU而言,图形输出规格与视频编解码能力也是一个相当重要的参数,在这方面Blackwell自然也是不遑多让。本次RTX 50系GPU全面支持包括DP2.1 80Gbps在内的先进视频输出规格,在消费级GPU中鹤立鸡群。同时,NVENC与NVDEC分别升级到第九代与第六代,支持了AV1 UHQ、MV-HEVC与4:2:2规格视频的编解码,而同时基础的H.264解码效率也同样令人啧啧称奇。无论是多屏用户还是多媒体创作者,都能够得益于Blackwell架构带来的显著提升。
第四代RT Core在第三代Ada 光追单元的基础上将三角形引擎拆分成求交与解压引擎,并引入了线性扫描球体引擎,能够大幅提升光追单元的计算效率,配合前文提到的在GPU微架构与显存技术上的提升,提升幅度不可小觑。
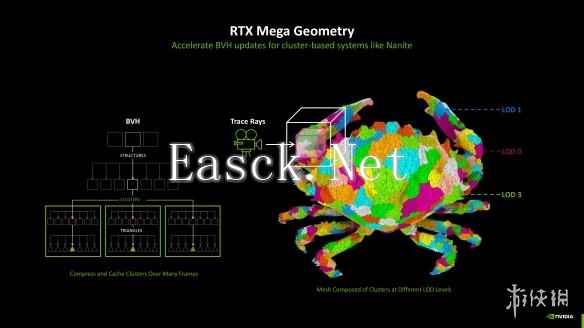

在先进的光追单元加持下,本次RTX 50系Blackwell GPU引入了全新的RTX Mega Geometry与硬件加速曲线基元,结合前面架构分析时提到的神经网络着色器能够为开发者提供更多样的可能性,带来革命性的画面表现能力与游戏体验。
凭借着高性能的光流加速器与游戏开发商的深度合作,RTX 40系Ada 架构搭载的DLSS 3功能可以说是广受好评,去年推出的DLSS 3.5光线重建技术更是让玩家们在如《赛博朋克:2077》与《心灵杀手2》这样的游戏中享受了数百小时的视觉盛宴,笔者自己就专程为了体验《心灵杀手2》这部Remedy Entertainment十年磨一剑的神作专程组装了一台搭载GeForce RTX 4080 SUPER 显卡的旗舰台式主机。而随着本次RTX 50系游戏显卡一并发布的全新技术 – DLSS 4更是在现有的帧生成管线上进一步拓宽了上限。

本次DLSS 4的一大亮点就是引入了Transformer模型替换了以往的卷积神经网络模型架构。传统的卷积神经网络模型架构在多年的更新中已经触及了性能极限,而全新的Transformer架构的性能不仅已经在Stable Diffusion等AI图片生成应用、ChatGPT等大语言模型中已经得到一次次的证实,而且它有能力根据画面的上下文进行推理,能够带来更稳定且符合逻辑的画面,减少鬼影、闪烁等现象随着DLSS 4的上线,包括超分辨率、帧生成在内的全套功能都将由更先进的Transformer模型驱动,带来显著提升的画面表现。

在这套截取自《心灵杀手2》亮瀑镇警局后院的对比图中,我们可以看到引入Transformer模型后,DLSS光线重建功能的画面表现得到了显著的提升。由于Transformer模型有能力通过“上下文”实现对画面的整体理解,在栅栏上我们能够明显看到铁丝的质感更为真实,而基于卷积神经网络模型的DLSS光线重建实现则由于卷积神经网络模型依赖卷积核的特性在这类场景中表现并不出色。

即使在像《地平线:西之绝境》这样不支持DLSS光线重建,仅支持DLSS超分辨率的游戏中,我们也能看到类似的改善。埃洛伊背包上的皮革线条在Transformer模型加持的DLSS超分辨率后仍然保持了相当明显的立体感,玩家可以显著的看到这个背包的缝制线条,对于游戏整体画面表现提升十分显著。
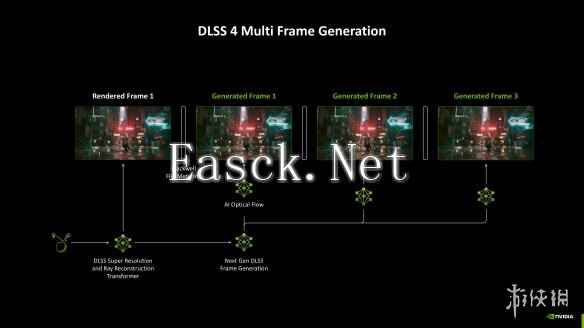
除了底层架构的革新之外,DLSS 4的另一大亮点就是它引入了多帧生成功能,允许游戏在DLSS 3帧生成技术的基础上生成更多帧数。同时,由于需要高效生成游戏画面,本次DLSS 4也引入了全新的AI光流算法以替代硬件光流加速器来加速光流场计算。综合而言,这套全新的DLSS 4能够带来40%的速度提升,同时还能降低30%的显存占用,可以说是相当强悍了。

在《战锤40K:暗潮》中,DLSS 4多帧生成能够实现最高画质下4K 137帧的游戏体验,提升高达10%,同时显存占用也比DLSS 3降低了0.4GB,为游戏开发者提供了更多空间用于引入高质量的画面技术。

而当我们将DLSS 4多帧生成技术与之前所有DLSS技术放在一起考虑时,我们会发现,目前DLSS技术已经能够做到让每十六个像素点中有15个由AI生成。在传统图形渲染架构革新与制程进化速度不断放缓的今天,依靠AI加速的DLSS而非暴力堆彻硬件规模(尽管NVIDIA在这方面也同样是武林高手)反而能够带来更显著的游戏体验上的提升。
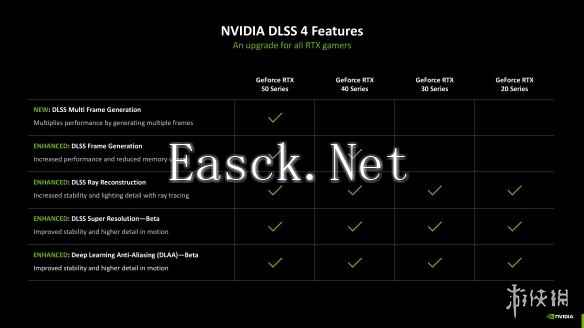
而对于之前已经购买过NVIDIA GeForce RTX GPU的玩家而言,本次DLSS 4在底层架构上的提升也同样能够让诸位受益,正如我们曾经在DLSS 3.5光线重建上见到的一样。
自从初代NVIDIA Reflex低延迟技术于2020年正式上线以来,这项通过优化游戏图形渲染以降低系统延迟的技术就在整个业界广受好评。无论是游戏开发商、外设厂商还是玩家都乐见并广泛接纳了这项极富盛名的技术,日前已有超过百款热门游戏进行支持,其中不乏如《反恐精英2》、《无畏契约》等热门电竞大作,它也是DLSS 3帧生成功能实现高可用性的重要基石。
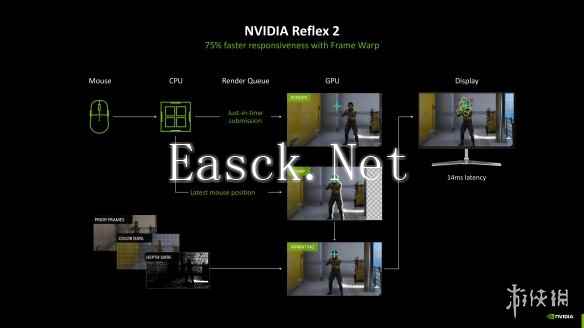
而随着图形技术复杂度越来越高,NVIDIA Reflex 2也应运而生。它在初版Reflex的基础上引入了全新的Frame Warp技术,能够基于鼠标输入预判下一帧的画面,进一步降低系统延迟。
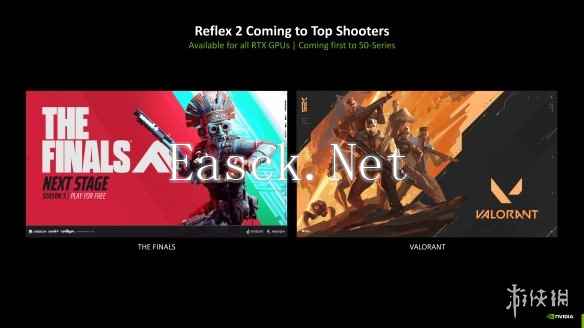
针对Reflex 2实现首发支持的两款游戏分别将会是The Finals与无畏契约,而这项技术尽管首发支持RTX 50系GPU,将会在未来扩展到全部RTX GPU阵容,让所有现代NVIDIA GeForce GPU的游戏用户体验到次世代的电竞体验。
本次我们评测的GPU是RTX 50系GPU矩阵中的次旗舰产品-GeForce RTX 5080。这颗GPU基于完整的GB203核心打造,拥有7组GPC单元,42组TPC单元,84组SM单元,共计10752组CUDA核心。尽管仍然基于TSMC的4N定制工艺打造,但RTX 5080 GPU在前文提到的Tensor Core、RT Core、NVENC/DEC编解码器上都有显著提升,辅以全新的30Gbps GDDR7显存颗粒,在显存位宽保持256bit的前提下将显存带宽从上一代RTX 4080的716.8GB/s提升到960GB/s,在高带宽要求的现代游戏、图形专业应用与AI负载下能够带来十分可观的提升。全面的提升带来了整卡的功耗的小幅上涨,从320W TGP上涨到360W,但考虑到增幅只有40W,现有RTX 4080/RTX 4080 SUPER的用户应当可以在不更换任何配件的情况下直接升级。
ADVANCED系列作为iGame家族高端显卡的中流砥柱,新一代RTX 50系的iGame Advanced系列显卡在经典设计的基础上进行了再生产。从神秘的环状星系哈氏天体中汲取灵感的红圈“引力之环”设计,以及其上铭刻着的产品铭文仍然得以保留,让老用户能够一眼看出这就是他们熟悉的那个设计。

但与此同时,本世代产品引入了更多的圆角和曲线元素,在显卡正面引入了一个灵感取自莫比乌斯环的∞设计,带来了相当新颖的视觉观感。同时,在配色上,本次的iGame GeForce RTX 5080 Advanced OC 16GB显卡也引入了更多黑、灰等暗色调,对整卡的色彩风格进行了一次全面升级。

看到侧面,本次的iGame GeForce RTX 5080 Advanced OC 16GB采用了双槽挡板的设计,但卡身仍然是较厚的,尺寸来到了69.3mm,接近三槽多宽度。更厚的散热模具对显卡温度的压制与性能的释放都有好处,这点就看各位装机时的取舍了。在挡板上,除了RTX 50系通用的DP 2.1 80Gbps接口与HDMI 2.1 48Gbps视频输出接口外,我们还看到了iGame家族祖传的一键超频按钮,这项功能一直因为其能够方便玩家在将显卡装入机箱后可一键切换VBIOS而广受好评,相信也会帮到很多用户。

iGame GeForce RTX 5080 Advanced OC 16GB显卡的星环背甲通过螺丝与其他部分连接,能够有效提升下整体结构的稳定性,同时环形的开孔设计也相当有利于风道构建,让气流能够有效通过。同时,背部散热孔还通过视觉上的特殊设计,让用户在横插状态下也能够看到iGame的LOGO,十分具有设计感。

当然,为了应对显卡的重量,七彩虹还随iGame GeForce RTX 5080 Advanced OC 16GB附赠一套iGame金属显卡支架 ,可以保护主板PCIe插槽与显卡PCB,让电脑在长期使用中更为可靠。
iGame GeForce RTX 5080 Advanced OC 16GB显卡正面的三把风扇装配了大口径“风镰”扇叶,能够使空气形成旋涡吸入,提升冷风的风压,增加进风量。这套风镰扇叶也是本次旋涡散热装置的核心技术,九片扇叶如镰刀般锋利,并环环相连地安装在显卡上,搭配双滚珠轴承电机,能够性能噪音两手抓。

iGame GeForce RTX 5080 Advanced OC 16GB散热模组采用VC均热板+7*8mm回流焊热管+导流型鳍片三板斧豪华设计,搭配铝合金中框带来了相当富裕的散热余量,能够轻松压制显卡的发热。
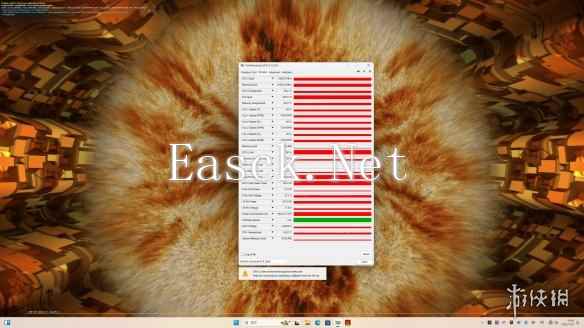
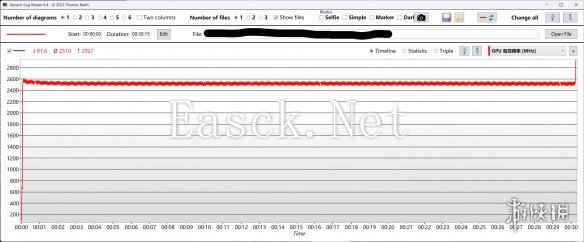
在25度室温30分钟FurMark压力测试中,这张iGame GeForce RTX 5080 Advanced OC 16GB显卡一直维持在稳定的370W功耗下,频率波动也近乎是一条直线。同时,GPU核心回报的温度控制也相当出色。
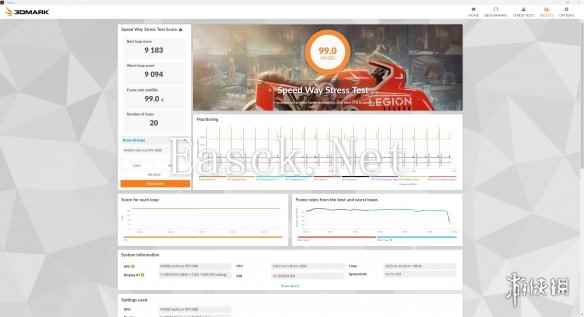
而在更贴近实际游戏应用的3Dmark Speed Way压力测试中,这张iGame GeForce RTX 5080 Advanced OC 16GB也取得了帧率稳定度99%的成绩,这套旋涡散热装置确实相当强劲。
为了全面发挥这张iGame GeForce RTX 5080 Advanced OC 16GB显卡的性能,七彩虹为我们提供了全套的板卡套装,我们最终用如图所示的配置组装了一台测试PC。
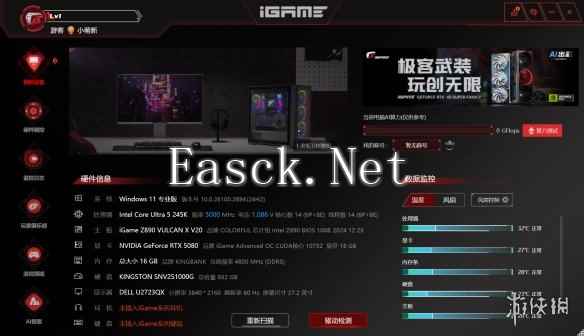
采用全家桶的一大好处是,用户可以使用iGame Center软件进行全面的监控与性能调优。除了我们之前见识过的RGB灯效和显卡超频之外,我们还可以使用更多样的配置方式进行深度配置,这一点就相当方便了。



在iGame全家桶的加持下,整机的RGB灯效能够轻松同步,效果十分出众

前文提到的iGame金属显卡支架也能够有效地支撑起显卡的重量,装机体验相当出色。
NVIDIA为我们提供了一套能够测试DLSS 4理论性能的3Dmark副本,我们就先从DLSS 4测试开始。可以看到,即使使用DLSS 3技术,iGame GeForce RTX 5080 Advanced OC 16GB的性能仍然显著强于RTX 4080 SUPER,而且幅度相当可观,甚至在引入Transformer模型和全套DLSS 4技术后还能再高出约10帧。从这个对比可以看出来,RTX 50系GPU中引入的、用于替换硬件光流加速器的AI确实是相当高效的存在,DLSS 4在实际游戏中的性能表现十分值得期待。
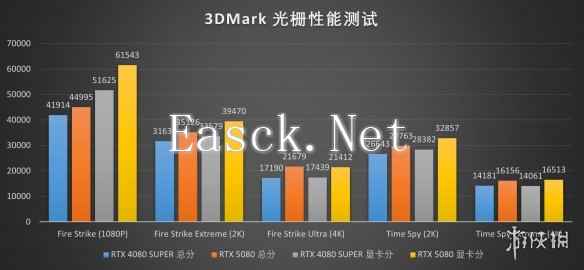
既然都测了DLSS,那我们不妨把其他所有项目都测一遍。在传统的光栅性能测试项目中,iGame GeForce RTX 5080 Advanced OC 16GB的表现相当可观,即使只考虑显卡分数也有断崖式的领先,在Fire Strike这一传统的1080P DX11性能测试中更是直接提升了10000分,这样的性能进化幅度意味着即使你玩的游戏并不支持DLSS,iGame GeForce RTX 5080 Advanced OC 16GB带来的提升也一样相当可观。
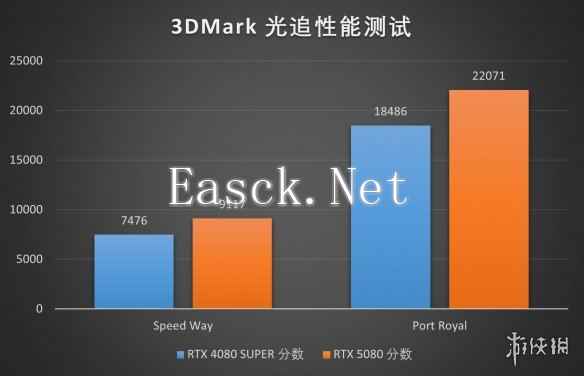
3Dmark提供的两项RTX性能测试里我们也看到了类似的显著提升,iGame GeForce RTX 5080 Advanced OC 16GB作为一张次旗舰级别的非公RTX 5080 GPU,性能表现在已经很强的RTX 5080 显卡基础上实现了再进化,相当适合发烧游戏玩家。
说了这么多,终于要开始打游戏了。考虑到GPU规模和定位,本次评测将只专注于4K性能,并且基本都在游戏提供的最高画面预设下进行游戏。

首先是《心灵杀手2》, 这款游戏是首批支持DLSS 4支持作品中相当突出的一款,这主要是因为它是首款引入NVIDIA RTX Mega Geometry技术的游戏,这项技术能够智能地集中处理并更新复杂几何,实时进行光线追踪计算,不仅可以降低GPU占用率、提高游戏帧率,还能够降低复杂光线追踪场景下的显存消耗。同时,至少在我们测试使用的开发者预览版中,Remedy开放了选择卷积神经网络或Transformer模型的权限,这使得我们可以更全面的对比几个模式下的性能表现。然而,由于它原生针对DLSS 3.5开发的特性,这也是唯一一款我们在高画面预设+高光线追踪预设下进行测试的游戏。
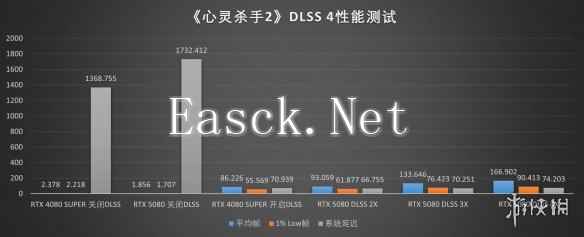
从数据上,我们可以明显地看到,由于Remedy Entertainment无需考虑基于古老GPU的第八世代主机产品,心灵杀手2能够以相当激进的方式引入包括全景光线追踪在内的各类现代图形技术和渲染技术,这款游戏的光追体验几乎可以说是强绑定DLSS光线重建与帧生成,而搭载RTX 50系GPU的iGame GeForce RTX 5080 Advanced OC 16GB显卡在这款游戏中的表现就相当惊艳。即使不开启多帧生成,完全依赖RTX 5080 GPU本身的架构升级与基于Transformer模型而非卷积神经网络的DLSS管线,心灵杀手也能够在高画面预设+高光追预设下轻松实现1% Low帧都有4K 60帧的表现,而在最高性能的DLSS 4X多帧生成模式下,目前最主流的4K 160Hz显示器都能够成为游戏的瓶颈,这对于心灵杀手2这款游戏来说确实令人震惊。

《赛博朋克2077》作为近几年NVIDIA展示图形技术革新的必备作品,在最新的2.21版本更新中也正式引入了DLSS 4技术,且同样允许玩家选择使用传统的卷积神经网络模型还是Transformer模型进行游戏,这也为我们提供了一个在实际游戏中探索两者表现的好办法。
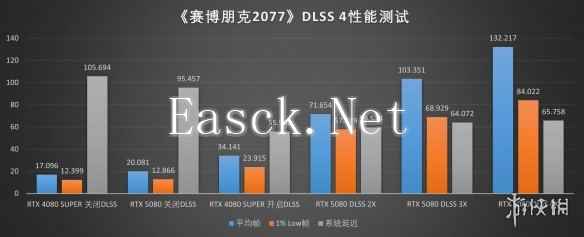
在赛博朋克2077中,我们使用光线追踪超速预设进行测试,而我们也同样能够看到基于Transformer模型而非卷积神经网络的DLSS在与高性能的RTX 50系GPU协作下的性能提升:DLSS性能几乎翻倍,从4K 30帧提升到1% Low帧都有4K 60帧,这样的性能提升对2077这样的一款依赖玩家操作的游戏而言提升十分显著。
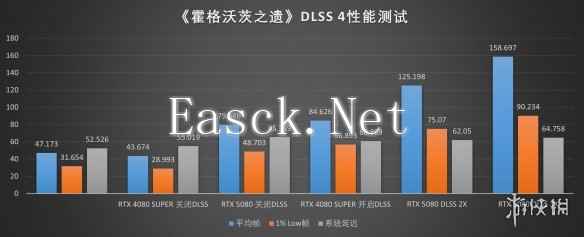
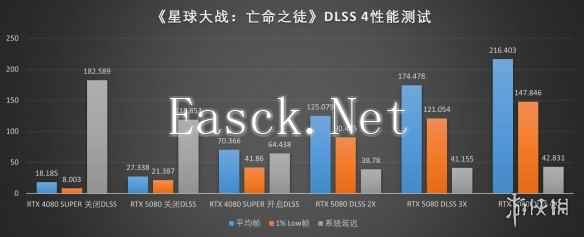
当然了,在《霍格沃茨之遗》与《星球大战:法外狂徒》这两款同样引入DLSS 4技术的游戏中,我们也能看到类似规模的性能提升。可以说,从这四款游戏中我们可以看出,iGame GeForce RTX 5080 Advanced OC 16GB在RDLSS 4的加持下可以在游戏中实现相当可观的性能提升,对于追求高性价比的4K高刷游戏体验而言相当出色。
当然了,除了我们上面测试的四款游戏之外,还有很多游戏暂未引入DLSS 4支持。同时,尽管玩家可以通过NVIDIA App优设功能在部分游戏中实现手动开启DLSS 4,我们出于数据可用性的考虑在这篇评测中将只覆盖那些已经支持的游戏。而对于像《黑神话:悟空》这样的暂未引入DLSS 4的游戏,我们也只能简单看看在DLSS 3的技术上,iGame GeForce RTX 5080 Advanced OC 16GB到底能带来怎样的提升了。
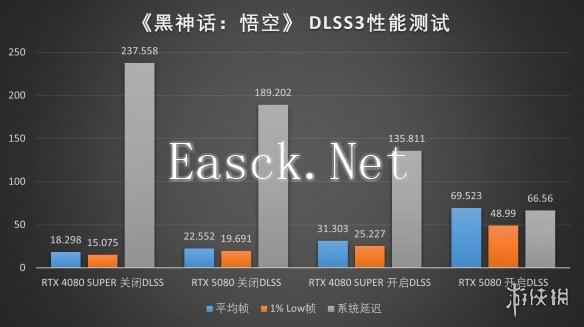
由于《黑神话:悟空》暂未引入DLSS 3.5光线重建技术的支持,它对性能的要求其实相当可观,两张显卡在原生渲染下都带来了并不出彩的成绩,但在Blackwell架构创新与iGame Advanced系列旋涡散热模块设计加持下带来的两板斧性能提升,iGame GeForce RTX 5080 Advanced OC 16GB显卡在DLSS 3下亦能实现翻倍的性能提升,表现也同样优异。
对于工业级AI比较了解的读者一定听说过MLPerf的大名。作为行业标准级别的AI测试套件,我们本次引入了MLPerf Client这一面向端侧应用的AI测试套件。它基于Meta开源的LLaMa 2模型,能够有效测试系统在常见AI负载下的理论性能,我们以Token Generation Rate值为基准进行比较。可以看到,在所有四种负载中,iGame GeForce RTX 5080 Advanced OC 16GB显卡都显著超越了作为基准的RTX 4080 SUPER GPU,这意味着在各类AI应用中,这张全新的iGame GeForce RTX 5080 Advanced OC 16GB都能够带来更高效能的表现。

除了偏理论的MLPerf Client,我们还能够通过Procyon套件测试RTX 5080显卡在文生图与LLM应用下的实际性能表现,先来看看文生图。Procyon的文生图测试基于FLUX.1 Dev模型实现,能够分别测试FP4与FP8规格下的性能表现,这张表记录的则是生成一张图所需的平均时间。可以看到,iGame GeForce RTX 5080 Advanced OC 16GB在FP4或FP8下都拥有相当可观的性能提升,尤其是在RTX 50系第一次原生支持的FP4格式下,性能提升更是相当显著。对于日常使用的AI负载来说,采用FP4这样的低精度格式能够在不损失实用性的前提下显著提升效率,十分好用。

而在大语言模型测试环节,我们也看到了不可小觑的性能进步,尤其是在显存吞吐量更高的LLaMa大模型里。考虑到目前已经有很多在本地部署像Qwen或DeepSeek这样的大语言对话模型的方案,iGame GeForce RTX 5080 Advanced OC 16GB带来的性能提升显然是十分可喜的。

当然,并非所有生产力应用都引入了AI加速,那作为算力基座,这张iGame GeForce RTX 5080 Advanced OC 16GB表现如何呢?我们使用同样属于业界标准的SPECviewperf 2020 V3.1进行了全套的性能测试。从结果上可以看到,iGame GeForce RTX 5080 Advanced OC 16GB显卡实现了相当可观且大幅度的领先,尤其是在Maya与Solidworks两项个人用户相当多的测试中提升十分显著。
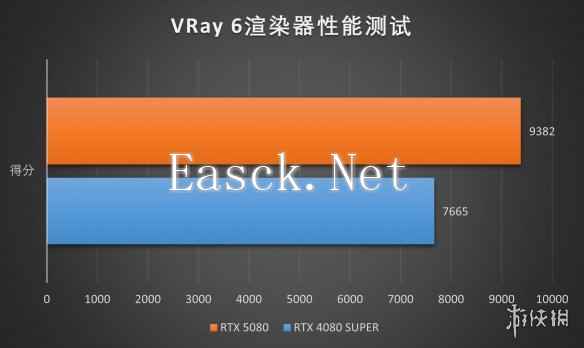
而Vray6渲染器测试中,我们也看到了相当出色的性能表现。
作为iGame家族的次旗舰型号,iGame GeForce RTX 5080 Advanced OC 16GB不仅继承了系列一贯的设计语言与视觉符号,还在现有的设计基础上实现了大刀阔斧又细致入微的进化,让本就广受好评的AD-OC系列显卡在RTX 50系这一重大图形技术革命节点更令人爱不释手。同时,由强大的旋涡散热装置支持的高性能规格也让这张显卡在性能上超越一众RTX 5080选手,进一步提升了自己的优势。可以说,对于预算充足且拥有大尺寸机箱的玩家而言,这张iGame GeForce RTX 5080 Advanced OC 16GB绝对是不容错过的优秀显卡。
在发稿时,这张iGame GeForce RTX 5080 Advanced OC 16GB已在包括七彩虹官网商城与京东、天猫、拼多多、抖音等线上渠道以及全国授权零售经销商在内的全部渠道全面上市开售。而除了它以外,七彩虹iGame家族这次还一并推出了Vulcan、Neptune、Ultra等多个不同系列的GeForce RTX 5080显卡产品供用户选购,对于想要升级RTX 50系的玩家而言,七彩虹iGame家族的显卡产品也同样值得考虑。
0



 三国:谋定天下
三国:谋定天下 侠盗猎车手:罪恶都市
侠盗猎车手:罪恶都市 离火之境
离火之境 幻唐志
幻唐志 辐射:避难所Online
辐射:避难所Online 王者荣耀
王者荣耀- 1和平精英
-
1

- 2香肠派对
-
2

- 3火龙复古
-
3

- 4暗黑破坏神2.7 重制版
-
4

- 5战场女神
-
5

- 6战神之决战西伯利亚
-
6

- 7黎明召唤
-
7

- 8超神之刃
-
8








